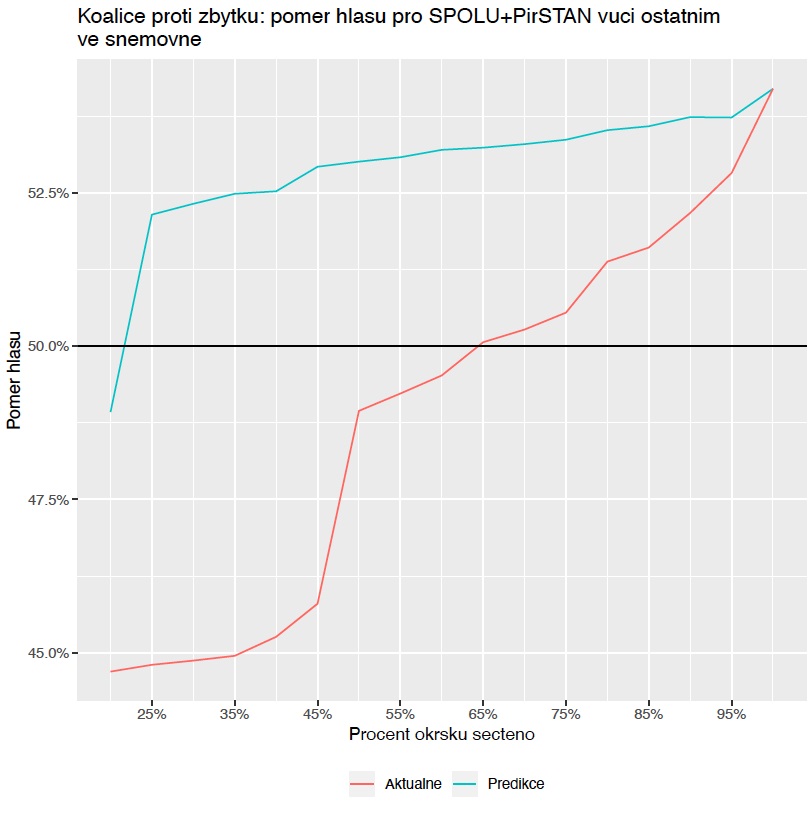
Byly to dramatické parlamentní volby. Kdo sledoval volební predikci na serveru iRozhlas.cz, musel během sobotního odpoledne smeknout. Docent Marek Omelka a Ondřej Týbl z katedry pravděpodobnosti a matematické statistiky MFF UK vyvinuli totiž pro portál Českého rozhlasu (ČRo) unikátní predikční model výsledku voleb. Odhad pracoval s postupně přibývajícími průběžnými daty, a byl tak neustále zpřesňován. Zatímco ostatní média během sčítání hlasů „pouze“ informovala o aktuálních číslech od Českého statistického úřadu, tento model dokázal výrazně přesněji odhadnout finální výsledky! „Při sečtení teprve dvaceti procent volebních okrsků jsme si byli na základě předpovědi našeho modelu docela jistí, že koalice Spolu a PirSTAN bude mít většinu v Poslanecké sněmovně,“ říká pro magazín Forum Ondřej Týbl.

Jak jste při vývoji predikčního modelu uvažovali a postupovali?
Marek Omelka: Nejprve jsme si museli vůbec ujasnit, jak volby probíhají. A vzít v potaz známou skutečnost, že na začátku sčítání jsou úspěšnější strany, která mají relativně větší podporu v malých volebních okrscích (což v době před volbami byly ANO, SPD, KSČM a ČSSD – pozn. red.), jejichž výsledky bývají známy nejdříve. S postupujícím časem však začínají být známé i výsledky ve větších - typicky městských okrscích -, což zlepšuje naopak výsledky stran, které mají relativně větší podporu spíše mezi městskými voliči: zejména ODS, Piráti a TOP 09. Naším úkolem tak bylo odhadnout, jak moc se budou zhoršovat výsledky stran z první skupiny, a naopak jak moc se zlepší výsledky stran z druhé skupiny.
Jak jste tuto disproporci vyřešili?
Marek Omelka: Použili jsme metodu běžně užívanou při odhadech volebních preferencí, ale i leckde jinde ve výběrových šetřeních, kdy z docela malého vzorku lidí, řádově tisíců, se snažíme odhadnout poměrné zastoupení v daleko větší populaci – například v celé České republice.
Agentury, které se takovými průzkumy zabývají, porovnávají známou demografickou strukturou velké populace s demografickou strukturu svého vzorku a podle toho dají různým respondentům ve vzorku různou váhou. Velmi zjednodušeně řečeno, když například zjistí, že jsou v jejich vzorku muži nadreprezentováni, dají jim menší váhu, a naopak zvýší váhu žen. Rozhodli jsme se zkusit to udělat podobně (oba vědci na snímku při komunikaci s autorkou článku).
Můžete to čtenářům podrobněji vysvětlit?
Marek Omelka: S pomocí voličských preferencí v posledních parlamentních volbách jsme rozčlenili okrsky do několika homogenních skupin – ve statistické teorii se jim říká strata. Určili jsme predikci jako vážený průměr již pozorovaných hlasů, přičemž váhy jsme zvolili tak, abychom vyrovnali aktuální zastoupení každého strata okrsků se zastoupením daného strata v celé České republice. To je takzvaná metoda převažování. Tedy například tvoří-li okrsky daného strata deset procent voličské populace, ale v dosud sečtených okrscích je to pouze pět procent, dáme hlasům z těchto okrsků dvojnásobnou váhu.
Takhle jste to tedy vymysleli ještě před samotným sčítáním?
Ondřej Týbl: Skupiny jsme si definovali už před začátkem voleb. V jejich průběhu se již přepočítávaly pouze zmíněné váhy. Totiž jak přibývaly nové okrsky, měnilo se zastoupení jednotlivých strat v již sečteném vzorku a na to musel umět náš model reagovat.
Jak si váš predikční model na iRozhlas.cz stál ve srovnání s aktuálními průběžnými volebními výsledky, o nichž referovala ostatní média?
Marek Omelka: Většina médií reportovala aktuální stav. iRozhlas měl zájem přinést predikční model, protože věděl, že aktuální průběžný stav je samozřejmě zkreslený. Okrsky, jak se postupně sčítají, dobře nereprezentují Českou republiku. V Českém rozhlase chtěli díky nám docílit přesnějšího odhadu toho, jak to nakonec dopadne. A ten odhad byl opravdu významně lepší než aktuální stav, který poskytoval médiím Český statistický úřad (ČSÚ).
Co konkrétně bylo největší přidanou hodnotou vašeho modelu?
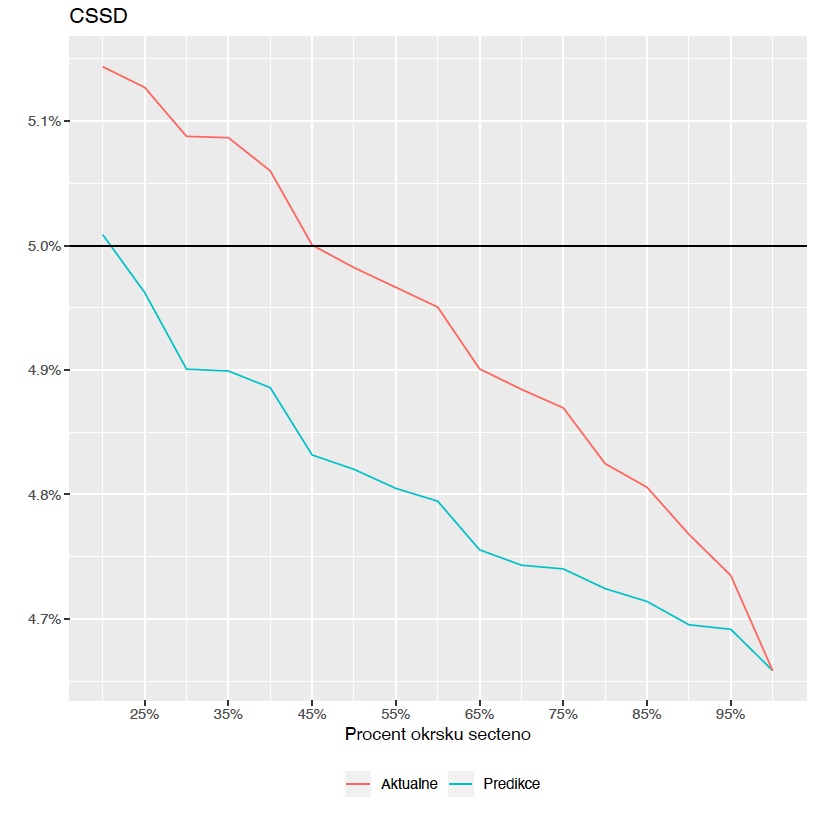
Ondřej Týbl: Vypíchl bych tři body. Už kolem pětadvaceti procent sečtených volebních okrsků jsme si byli poměrně dost jisti, že výsledná koalice Spolu a PirSTAN bude mít většinu ve sněmovně. Což z aktuálních výsledků dosud sečtených okrsků nebylo vidět ještě docela dlouhou dobu... Muselo se čekat, než vypadne z Poslanecké sněmovny ČSSD a KSČM, plus koalice Spolu ještě musela nabrat nějaké hlasy.
Takže jste viděli dříve, než se to potvrdilo ze sečtených okrsků, že se ČSSD a KSČM nedostanou do sněmovny?
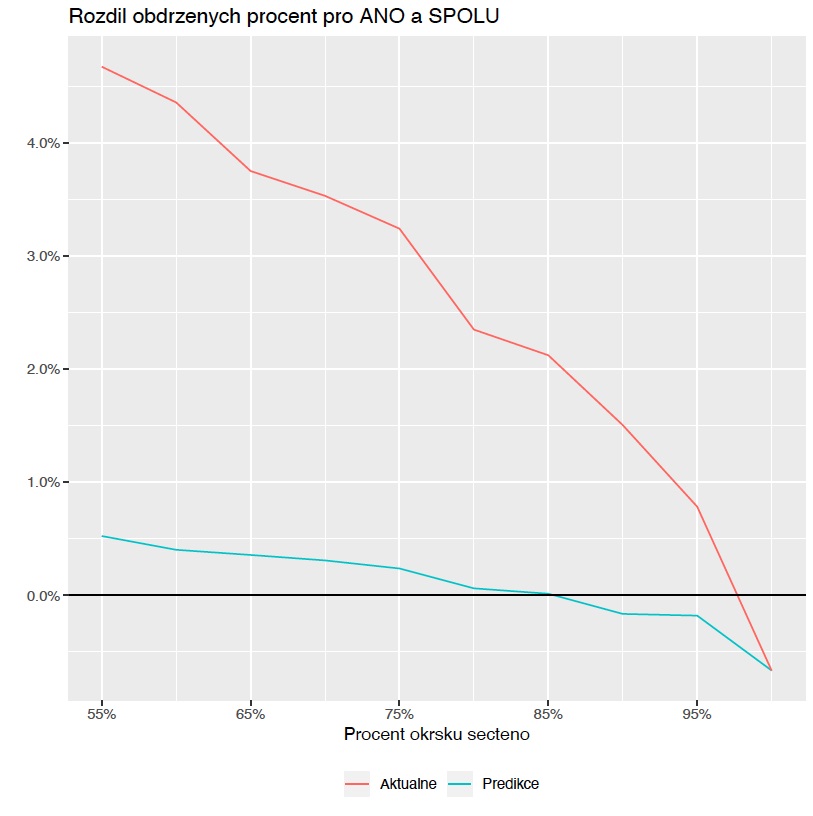
Ondřej Týbl: To je ten druhý bod. U komunistů to bylo docela brzy zjevné i z aktuálních výsledků, ale u ČSSD to bylo patrné až u pětačtyřiceti procent sečtených okrsků. A my jsme to přitom viděli o dost dřív. Velmi sledovaný byl také souboj ANO a Spolu. Na první pohled nebylo jasné, jak to dopadne ještě ve chvíli, kdy zbývalo dopočítat tři procenta okrsků. Přitom naše predikce se správně začala klanět na stranu poněkud překvapivého vítěze již těsně po 85 procentech sečtených okrsků.
Na webu iRozhlasu je popsáno, na jakém principu váš model funguje. Mohl by to nějaký jiný matematik využít jako know-how k vytvoření vlastního, řekněme, konkurenčního modelu?
Ondřej Týbl: Ve zmíněném popisu jsou uvedeny klíčové matematické pojmy a pro člověka, který je zná, je to přinejmenším dobrý návod. Asi by se mu to nepodařilo zpracovat úplně stejně, ale určitě k tomu bude mít dobře nakročeno.
Marek Omelka: Metoda převažování je ve statistické teorii známá a velmi dobře s ní umějí pracovat lidé, kteří se zabývají populačními průzkumy. To, co je v našem modelu nejtěžší, je nalézt homogenní skupiny – ona strata – volební okrsky, v nichž lidé volí podobně. A následně je nutné promyslet, kolik těch strat použít. Teoreticky je postup docela jasný, ale, jak se říká, ďábel tkví v detailech implementace. A já jsem hrozně rád, že do toho Ondřej se mnou šel. Opravdu si s tím pohrál a věnoval tomu čas.
Ondřej Týbl: Implementoval jsem nápady, které přinesl pan docent Omelka, a vytvořil z nich kód, respektive matematický model, který je schopen něco spočítat.
Marek Omelka: Rozhodně to ale není tak, že Ondřej jen naprogramoval něco, co jsem mu řekl (usmívá se). Tak jednoduché to není. Během programování přicházel a upozorňoval na řadu problémů týkajících se například změn velikostí volebních okrsků. Vytvářel řadu průběžných analýz, na jejichž základě jsme postupně dolaďovali zásadní detaily.
Plánujete připravit predikční model i pro další volby?
Marek Omelka: Asi bychom do toho znovu šli; pokud bude ze strany Českého rozhlasu zájem. Na této spolupráci je nám oběma sympatické to propojení Univerzity Karlovy a veřejnoprávního média, které dělá seriózní zpravodajství, a navíc i kvalitní datovou žurnalistiku. Ale samozřejmě je to pro nás veliký závazek a zodpovědnost, protože, zvlášť při takovémto predikování v reálném čase, může jedna, takříkajíc hloupá chyba, vrhnout velice špatné světlo na naši katedru, Matematicko-fyzikální fakultu UK, potažmo celou Univerzitu Karlovu. A to bychom velice neradi.















